本文共 2444 字,大约阅读时间需要 8 分钟。
谈笑间学会数仓—维度层设计④
极限存储
1.1、历史拉链存储
历史拉链存储是指里用维度模型中缓慢变化维的第二种处理方式。这种处理方式是通过新增两个时间戳字段(start_dt 和 end_dt 命名仅供参考),将所有以天为粒度的变更数据记录下来。通常分区字段也是时间戳字段。
举个例子:2020年1月1日,卖家A在淘宝网发布了B、C两个商品,前端商品表将生成两条记录t1、t2 ; 1月2日,卖家A将B商品下架了,同时又发布了商品D,前端商品表将更新记录t1,又新生产记录t3; 采用全量存储方式,在1月1日这个分区中存储t1和t2两条记录;在1月2日这个分区中存储更新后的t1以及t2、t3记录。数据存储记录如下表所示。
| 商品 | dt | 卖家 | 状态 | 其他字段 |
|---|---|---|---|---|
| B | 20200101 | A | 上架 | … |
| C | 20200101 | A | 上架 | … |
| B | 20200102 | A | 上架 | … |
| C | 20200102 | A | 上架 | … |
| D | 20200102 | A | 上架 | … |
如果采用历史拉链存储,数据存储记录如表下表所示,对于不变的数据,不再重复存储
| 商品 | start_dt | end_dt | 卖家 | 状态 | 其他字段 |
|---|---|---|---|---|---|
| B | 20200101 | 20200102 | A | 上架 | … |
| C | 20200101 | 20200102 | A | 上架 | … |
| B | 20200102 | 99999999 | A | 上架 | … |
| C | 20200102 | 99999999 | A | 上架 | … |
| D | 20200102 | 99999999 | A | 上架 | … |
这样下游应用通过限制时间戳字段来获取历史数据即可。
例如:用户访问1月1日的数据,只需要限制start_dt<=20200101 和 end_dt>20200101即可。
但是这种存储方式对于下游使用方存在一定的理解障碍,特别是ODS数据面向的下游用户包括数据分析师、前端开发人员等,他们不太理解维度模型和概念,因此会存在较高的解释成本。另外这种存储方式用start_dt 和 end_dt 做分区,随着时间的推移,分区数量会极度膨胀,而现行的数据库系统都有分区数量限制。
为了解决上述的两个问题,阿里采用极限存储的方式来处理。
1、透明化
底层的数据还是历史拉链存储,但是上层做一个视图操作或者在Hive里做一个hook,通过分析语句的语法树,把对极限存储前的表的查询转换成对极限存储表的查询。对于下游用户来说,极限存储表和全量存储方式是一样的:
select * from A where ds = 20210101;-- 等价于select * from A_EXST where start_dt <= 20210101 and end_dt > 20210101
2、分月做历史拉链表
假设用 start_dt 和 end_dt 做分区,并且不做限制,那么可以计算出一年的历史拉链表最多可能产生的分区数是:365*364/2=66430个。如果在每个月月初重新开始做历史拉链表,目录结构如下(样例):

再计算一年最多可能产生的分区数是:12*(1+(30+29)/2)= 5232个。
采用极限存储的处理方式,极大地压缩了全量存储成本,又可以达到对下游用户透明的效果,是一种比较理想的存储方式。但是其本身也有一定的局限性,首先,其产出效率很低,大部分极限存储通常需要t-2; 其次,对于变化频率高的数据并不能达到节约成本的效果。因此,在实际生产中,做极限存储需要进行一些额外的处理。
- 在做极限存储前的一个全量存储表,全量存储表仅保留最近一段时间的全量分区数据,历史数据通过映射的关系关联到基线存储表。即用户只访问全量存储表,所以对用户来说极限存储是不可见的。
- 对于部分变化频率频繁的字段需要过滤。例如用户表中存在用户积分字段,这种字段的值每天都在发生变化,如果不过滤的话,极限存储就相当于每个分区存储一份全量数据,抢不到节约存储成本的效果。
微型维度
采用极限存储,需要避免维度的过度增长。比如对于商品维表,每天20多亿条数据,如果在设计商品维度时,将值变化频繁的属性假如到商品维度中,极限情况是每天所以商品数据都发生变化,此时,极限存储没有意义;反之,每天所有的商品数据都不发生变化,此时,只需要存储一天的数据即可。
通过将一些属性从维表中移出,放置到全新的维表中,可以解决维度的过度增长导致极限存储效果大大折扣的问题。其中一种解决方法就是垂直拆分,保持主维度的稳定性;另一种解决方式是采用微型维度。
微型维度的创建是通过将一部分不稳定的属性从主维度中移出,并将它们放置到拥有自己代理键的新表中来实现的。这些属性相互之间没有直接关联,不存在自然键。通过为每个组合创建新行的一次性过程来加载数据。比如淘宝用户维度,用户的注册日期、年龄、性别、身份信息等基本不会发生变化,但用户VIP等级、用户信用评价等级会随着用户的行为不断发生变化。其中VIP等级共有8个值,即 -1~6;用户信息评价等级共有18个值。假设基于VIP等级和用户信用评价等级构建微型维度,则在此微型维度中共有8*18个组合,即144条记录,代理键可能是1~144。
下面以淘宝交易事实表为例,其他维度忽略,星型模式可能表示如下图所示:
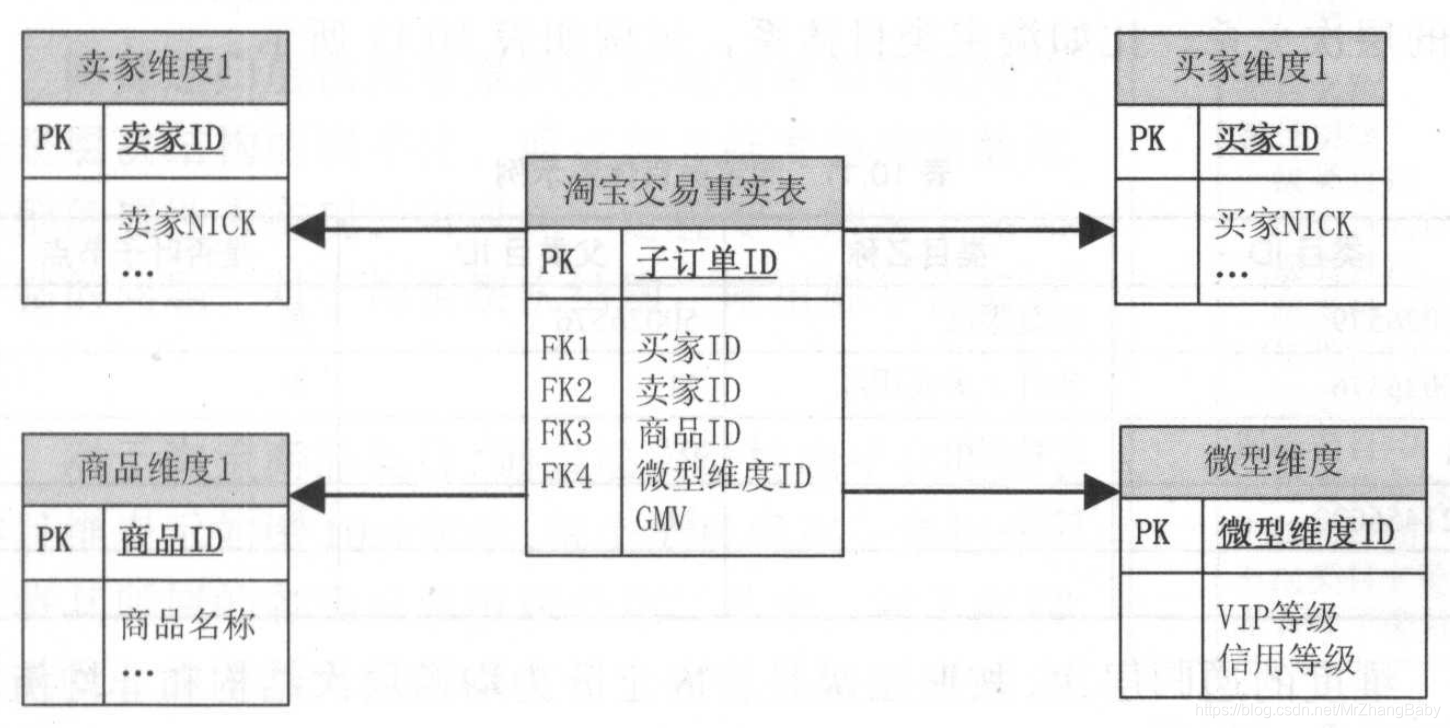
但是在数据仓库实际实践中, 有些并未使用此技术,主要有一下几点原因:
- 微型维度的局限性。微型维度是事先用所有可能值的组合加载的,需要考虑每个属性的基数,且必须是枚举值。很多属性可能是非枚举型,比如数值类型,如VIP分数、信用分数等;时间类型,如上架时间、下架时间、变更时间等。
- ETL逻辑复杂。对于分布式系统,生成代理键和使用代理键进行ETL加工都非常复杂,ETL开发和维护成本过高。
- 破坏了维度的可浏览性。买家维度和微型维度通过事实表建立联系,无法基于VIP等级、信用等级进行浏览和统计。可以通过在买家维度中添加引用微型维度的外键部分来解决此问题,但带来的问题是微型维度未维护历史信息。
参考:《大数据之路-阿里巴巴大数据实践》
转载地址:http://kcdxz.baihongyu.com/